‘Open AI’ has the word ‘Open’ in it. It was supposed to follow the open-source philosophy of ‘transparency’ and ‘collaboration’. Yet, it keeps many of its technological advances secret. It also dismantled the ‘open-source’ origins since the launch of ChatGPT that the whole technology world condemned it for.
While you are getting transparency on AI models from the launch of DeepSeek. The makers follow the ‘Open Source’ philosophy, and these belong to a company started in the land of CCP. One wouldn’t expect that.
We are living in strange times. The race to AI is testing everyone’s morals. It is heating up geopolitical competition like never before.
On one hand you have NVIDIA releasing better but expensive chips every quarter. The US restricted sending these latest chips to China to curb competition. On the other hand, DeepSeek is making its entire code open-source. Their model taught the world how AI can be made cost-effective and accessible.
We mere mortals can only grab a popcorn and watch this pure show of capitalism and geopolitics.
The movie begins with DeepSeek’s rapid rise. This is followed by NVIDIA’s recent stock plunge worth $600 billion market cap crash in early 2025. Initially, people blamed DeepSeek. It is a Chinese AI company. Their breakthroughs in cost efficiency and reasoning capabilities disrupted long-held assumptions and trajectories about the AI industry.
While market reactions stay debated, DeepSeek’s technical breakthroughs reveal a paradigm shift in efficient AI development that challenges OpenAI’s leadership.
Everyone covered headlines about the ‘geopolitics’ aspect of it. Here’s a sane comment I found on Reddit (where else would I find!)

Source: Reddit
DeepSeek is important because Open Source philosophy is catching up to Closed ones. Here’s the actual quote:

With this clear, in today’s AI Model analysis, I examine how the Chinese lab achieved frontier performance through architectural ingenuity rather than brute-force compute scaling.
Technical Architecture: Doing More With Less
DeepSeek’s most staggering achievement is its ability to train frontier models at a fraction of the cost of Western competitors.
The DeepSeek-V3 model, released in December 2024, required just 2.8 million GPU-hours and $5.6 million to train—10x cheaper than Meta’s Llama 3.1, which consumed 30 million GPU-hours.
Here are the three key innovations by DeepSeek that propelled this leap:
1. Optimizing the Mixture-of-Experts architecture
Mixture of Experts (MoE) is a machine learning architecture to improve the performance of AI models designed. At its core, MoE divides a large model into smaller, specialized sub-models. These are known as ‘experts’. Each expert is tailored to handle specific tasks or types of input data. This approach activates only the relevant experts for a given input. Doing so significantly reduces computational costs while still maintaining high accuracy.
Let’s understand this with an example, because it is critical to understand this concept to know what DeepSeek optimized:
Think of MoE as a team of specialists in a company. Instead of having one generalist who tries to do everything, you have several experts. Each expert excels in their own area (like a traditional AI model). For example, if you were running a restaurant, you will have:
- A chef who specializes in Italian cuisine
- A pastry chef who excels at desserts
- A wine steward who knows all about wines
When a customer orders a meal, the restaurant can direct the order quickly. They send it to the appropriate chef based on what is being requested. This targeted approach speeds up service. It also ensures that someone with the right expertise prepares each dish.
How Does Mixture-of-Experts Work?

Source: Mixture-of-Experts (MoE) LLMs by Cameron Wolfe on Substack
MoE operates through two main components: expert networks and a gating network.
- Expert Networks: These are the specialized models that focus on different aspects of the problem. Each expert is trained on different subsets of data, allowing them to develop deep knowledge in their specific area. For example:
- One expert can train to understand language nuances, making it great for tasks like sentiment analysis.
- Another expert can specialize in recognizing patterns in numerical data, which is useful for financial predictions.
- Gating Network: This component acts like a traffic director. When an input (a question or data point) is received, the gating network evaluates it. It decides which experts should be activated based on their specialties. It effectively routes the input to the most suitable experts for that particular task.
What did DeepSeek optimize in this MoE ML architecture?

Source: GeeksForGeeks
The optimization aspect of MoE lies in its ability to manage resources effectively while maximizing performance.
Here are some key optimization techniques implemented by DeepSeek:
- Sparsity: In MoE architectures, not all experts are activated at once. Instead, a small subset is used for each input. This sparsity reduces computational load significantly because fewer resources are needed compared to activating an entire model.
- Dynamic Activation: The gating network dynamically selects which experts to activate based on real-time analysis of incoming data. This means that as new types of queries or tasks arise, the system can adapt by activating different experts. It does not need extensive retraining.
- Weighted Outputs: Once the relevant experts generate their outputs, these results are combined using weighted averaging. The gating network assigns weights based on how well each expert performed on similar tasks in the past. This ensures that more reliable experts have a greater influence on the final output.
- Continuous Learning: As more data flows through the system, both experts and the gating network can learn from past interactions. If one expert consistently performs better than another for certain types of inputs, the system can favor it more often in future activations.
You can learn more about what DeepSeek did from its DeepSeek-V3 Technical Report.
The result of MoE optimizations by DeepSeek
By dynamically activating specialized neural sub-networks per task, V3 achieves 671 Billion parameter capacity while only using ~15% per query. This architecture reduces training/inference costs by 10x compared to dense models like Llama 3.1!
2. Memory Compression Breakthroughs by DeepSeek
As artificial intelligence models grow in complexity and size, the demand for memory and computational resources increases. This is particularly true for large language models (LLMs). This has led researchers to explore innovative solutions to optimize memory usage without sacrificing performance.
One of the most promising advancements in this area is FP8 Quantization.
What is FP8 Quantization?
FP8 Quantization is an optimization technique used in artificial intelligence (AI) and machine learning. It helps reduce the memory and computational requirements of models. FP8 quantization converts data from higher precision formats to lower precision formats. This conversion allows models to run faster and use less memory. It maintains acceptable levels of accuracy.
Quantization refers to the process of reducing the number of bits that represent a number in a model. In AI, this usually involves converting floating-point numbers. These numbers can represent a wide range of values. The conversion changes them into smaller, more manageable formats.
- Floating Point (FP): This is a way of representing real numbers that can have fractions (like 3.14 or 0.001). The most common formats are FP32 (32 bits) and FP16 (16 bits), which offer high precision but require more memory.
- Quantization: This is the process of mapping a large set of values to smaller sets. For example, converting numbers from FP32 to FP8 uses only 8 bits instead of 32. This reduction decreases the amount of data processed.
So, what would now FP8 quantization mean?
FP8 quantization specifically refers to using an 8-bit floating-point format for representing numbers in AI models. This format allows for a good balance between performance and numerical accuracy, making it particularly useful for large-scale models.
Still confused? Here’s an example to understand how FP8 quantization works:
Imagine you have a very detailed painting that you want to show on a digital screen. The original painting uses millions of colors (like using FP32). This gives it incredible detail but takes up a lot of memory.
If you want to show this painting on a smaller screen, you could reduce the number of colors to 256. This is similar to using FP8. Some detail may be lost. However, the painting will still look good enough for most viewers. It will take up much less space on your device.
Understanding DeepSeek’s Optimization in FP8 Quantization
Now let’s understand what DeepSeek did to improve it using the FP8 quantization:
- Adaptive Precision Management: Instead of applying FP8 quantization uniformly across all model parameters, DeepSeek employs adaptive techniques. Certain critical parameters may retain higher precision, like FP16, if necessary. This ensures that important calculations keep their accuracy while still benefiting from reduced memory usage elsewhere.
- Fine-Tuning with Mixed Precision: DeepSeek uses a mixed-precision training strategy where both FP16 and FP8 formats are used during training. This technique allows the model to learn effectively while gradually transitioning to lower precision formats for deployment.
- Enhanced Compression Algorithms: DeepSeek has developed advanced algorithms that intelligently compress numerical representations further without losing significant information. This means that even after quantization, the model can still execute complex tasks effectively.
- Dynamic Range Adjustment: The company has introduced mechanisms. These mechanisms adjust the dynamic range of values being quantized. The adjustment is based on their distribution in the training data. By doing so, it minimizes the risk of losing important details during the conversion process.
The result of FP8 Quantization by DeepSeek

Source: DeepSeek-R1: Transforming AI Reasoning with Reinforcement Learning and Efficient Distillation by Deepankar Singh on Medium
DeepSeek has set a new standard for efficiency in large language models. It has halved memory requirements. It has improved benchmark scores. It has reduced GPU needs for deployment.
DeepSeek V3 achieves 2.4x faster training vs standard 16-bit setups.
The quantized versions of DeepSeek models, such as DeepSeek-Coder-V2-Lite, achieved an average score of 79.60 on the HumanEval+ benchmark, compared to 79.33 for the unquantized model. Similarly, the DeepSeek-Coder-V2-Base model scored 80.55, up from 79.90 in its unquantized state 12. These scores indicate that the quantization process not only maintained performance but also improved it slightly in some cases.
The quantized models can now be loaded using only 4 H100 GPUs. They can also be evaluated with this smaller hardware set, as opposed to the previous requirement of 8 GPUs. This reduction in hardware requirements further emphasizes the efficiency gains achieved through FP8 quantization.
This allows 128k-token contexts on consumer GPUs – before requiring specialized hardware, that is, premium NVIDIA chips. When the AI community realized that this is not required, it led to stock plunge for NVIDIA!
3. Multi-Head Latent Attention (MLA)
Multi-Head Latent Attention (MLA) method aims to reduce memory usage. It maintains or even improves performance. This is especially true in the context of processing large datasets. To understand MLA fully, we need to break down its components and how it optimizes attention mechanisms.
What is Multi-Head Attention?
Before diving into MLA, it’s essential to grasp the concept of multi-head attention. In traditional multi-head attention, the model uses multiple “heads” to focus on different parts of the input data simultaneously. Each head learns to pay attention to various aspects of the input. This allows the model to capture a broader range of information.
Let’s understand this with an example:
Imagine a teacher trying to understand a group of students during a discussion. Instead of focusing on one student at a time, the teacher listens to several students simultaneously, each providing different perspectives. This way, the teacher gains a more comprehensive understanding of the topic being discussed.
What is Latent Attention?
Latent attention refers to a compressed representation of key-value pairs used in attention mechanisms. In standard attention mechanisms, every token generates a key and a value that represent its significance in understanding context. Yet, as models scale up, storing all these keys and values can lead to significant memory overhead.
How Does Multi-Head Latent Attention Work?

Source: DeepSeek Technical Analysis — (2)Multi-Head Latent Attention by Jinpeng Zhang on Medium
MLA improves upon traditional multi-head attention by implementing two key strategies:
Low-Rank Factorization:
Instead of storing full key-value pairs for each head, MLA compresses these pairs into a lower-dimensional latent vector. This means MLA uses compressed keys and values for each head. The compressed version can be expanded when needed. Low-rank factorization is like summarizing a long book into a short abstract. It captures all key points without losing essential information.
Dynamic Decompression:
When processing an input, MLA decompresses this latent vector back into full key-value pairs for each head on-the-fly. This allows the model to maintain the expressive power of distinct keys and values while significantly reducing memory usage. Think of it as having a digital library where you store only summaries (latent vectors) of books (key-value pairs). When someone wants to read a specific book, you can quickly expand the summary back into the full text!
Understanding DeepSeek’s optimization techniques in Multi-Head Latent Attention (MLA)
DeepSeek made several optimizations in MLA that set it apart from traditional multi-head attention:
- Compressed Key-Value Cache: MLA caches only the latent vectors instead of full key-value pairs. This approach drastically reduces memory usage—reportedly down to just 5–13% of what traditional methods require.
- Adaptive Processing: The model dynamically processes these compressed vectors. It tailors the processing based on the input data’s needs. This approach allows the model to maintain performance while using less memory.
- Enhanced Performance Metrics: In experiments, MLA was compared with standard multi-head attention and other techniques like Multi-Query Attention (MQA). DeepSeek found that MLA achieved better performance metrics. It also required significantly less memory.
Results from DeepSeek’s Experiments with MLA
DeepSeek conducted several experiments to evaluate the effectiveness of MLA compared to other attention mechanisms:
| Model | Training Perplexity | KV Cache / Token / Layer |
|---|---|---|
| MHA 35M RoPE | 94.31 | 8192 |
| MLA 35M RoPE | 96.70 | 2856 |
| MHA 35M Decoupled RoPE | 98.76 | 8192 |
| MQA 32M RoPE | 102.18 | 512 |
| MLA 35M no RoPE | 142.77 | 2728 |
| MHA 35M no RoPE | 147.83 | 8192 |
| MQA 32M no RoPE | 155.44 | 512 |
From this table, we can see:
- Lower Training Perplexity: A lower perplexity score indicates better performance in language modeling tasks. The MLA model outperformed other models when no Rotary Position Embeddings (RoPE) were used.
- Reduced KV Cache Size: The KV cache size per token per layer is significantly smaller for MLA. This is in comparison to traditional multi-head attention methods. This highlights MLA’s efficiency.
DeepSeek has developed an approach using low-rank factorization and dynamic decompression techniques. This approach not only reduces memory requirements but also maintains high performance levels across various tasks.
DeepSeek R1 advantage: Open-source reasoning model that embarrasses OpenAI O1 model
OpenAI’s o1 revolutionized AI reasoning in 2024 by generating intermediate ‘thinking tokens’. But its closed-source nature left researchers guessing about its architecture—until DeepSeek’s R1 arrived in January 2025.
- Transparent Reasoning: Unlike o1, which hides its thought process, R1 exposes its reasoning tokens. This transparency has made it a favorite for researchers.
- Self-Taught Problem-Solving: R1 learned advanced reasoning without human-curated examples. Using reinforcement learning, it iteratively solved problems, checked answers, and adjusted its approach—akin to AlphaZero’s self-play.
- Cost-Effective Training: R1 required no exotic architectures (e.g., “tree of thoughts”) and was fine-tuned from V3 for minimal additional cost.
Benchmarks show R1 matching o1’s performance on Olympiad-level math problems while costing users 90% less per query!
While OpenAI’s o1 remains shrouded in secrecy, DeepSeek’s R1 technical report reveals a streamlined approach to AI reasoning:
| Feature | DeepSeek R1 | OpenAI o1 (Estimated) |
|---|---|---|
| Architecture | Modified V3 base | Custom-built system |
| Thinking Tokens | Visible to users | Hidden |
| Training Method | Self-taught reinforcement learning | Human-curated reasoning trees |
| Context Window | 256k tokens | 128k tokens |
| Cost/Hour (Inference) | \$0.12 | \$2.50+ |
The following table summarizes key performance metrics for DeepSeek-R1 and OpenAI o1:
| Benchmark | DeepSeek-R1 | OpenAI o1-1217 |
|---|---|---|
| AIME 2024 | 79.8% | 79.2% |
| MATH-500 | 97.3% | 96.4% |
| Codeforces | 96.3% | 96.6% |
| SWE-bench Verified | 49.2% | 48.9% |
| GPQA Diamond | 71.5% | 75.7% |
| MMLU | 90.8% | 91.8% |
R1’s open-weight model allows third-party audits and customization – a stark contrast to o1’s black-box approach. Early benchmarks show R1 solving 82% of IMO-level problems vs o1’s 79%, despite using 40% less compute per query.
Are you using DeepSeek? – let me know some tricks you know and I can include them in my guide on using DeepSeek!
If not, here’s a crash course on DeepSeek by FreeCodeCamp that I found to be useful:
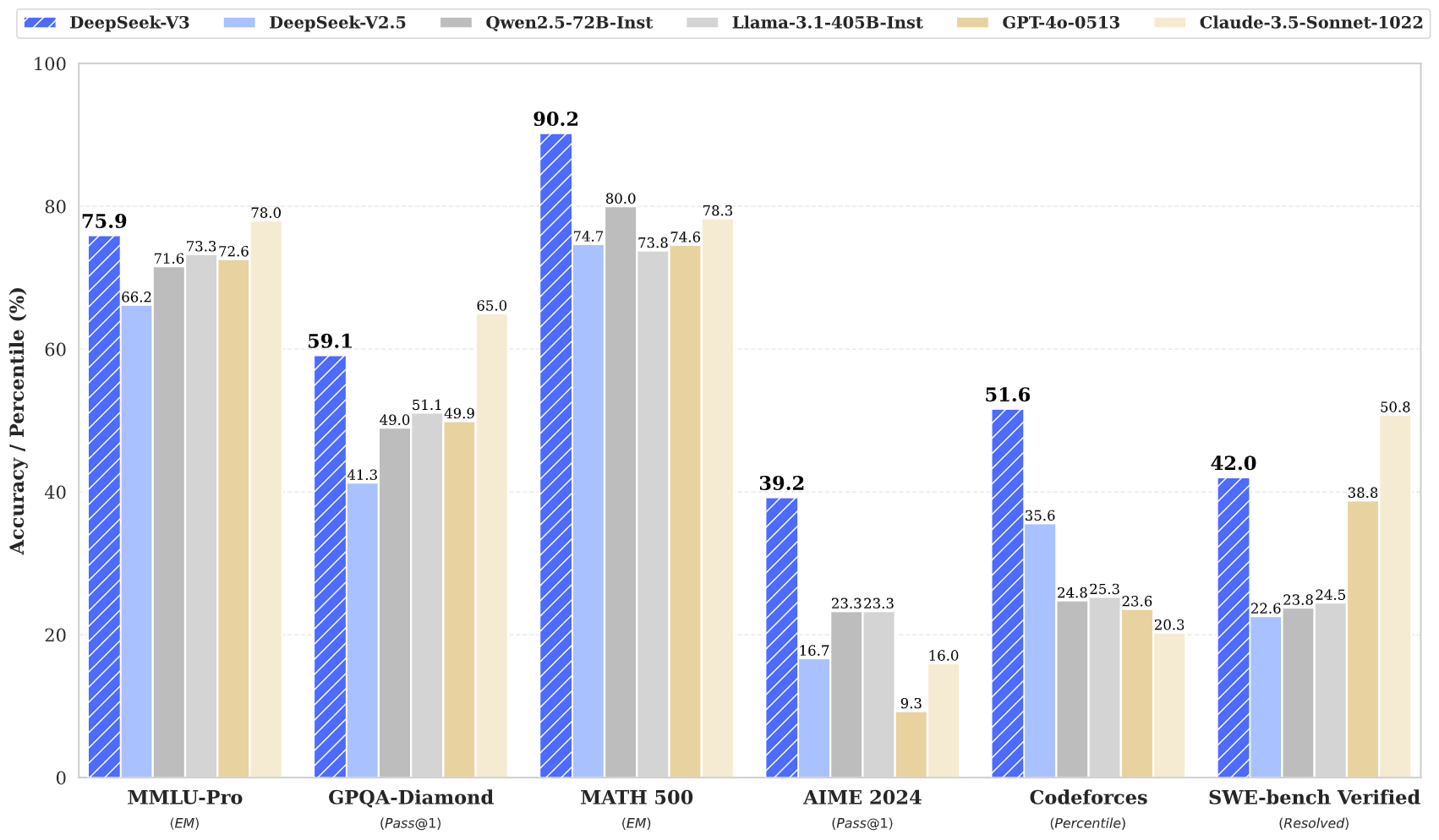
DeepSeek V3 performance benchmarks: beating the best with less

DeepSeek’s models consistently outperform open-source rivals and challenge closed leaders:
| Model | MMLU (5-shot) | AIME Math | Coding (HumanEval) | Training Cost |
|---|---|---|---|---|
| DeepSeek-V3 | 85.4% | 72% | 88.5% | $5.6M12 |
| GPT-4o | 86.1% | 68% | 87.2% | ~$100M (est.) |
| Claude 3.5 Sonnet | 84.9% | 65% | 85.7% | ~$80M (est.) |
| Llama 3.1-405B | 82.3% | 58% | 81.4% | ~$50M1 |
V3’s dominance in math (AIME) and coding highlights its lean specialization—a stark contrast to the “brute force” approach of larger models
The inference advantage: DeepSeek is cheaper, faster, longer
DeepSeek’s advancements in inference technology have led to significant improvements across several dimensions: cost, speed, and efficiency.
Here’s a closer look at these advantages that goes beyond training:
- Long-Context Mastery: MLA allows V3 to process 1M-token contexts efficiently, outperforming Claude 3.5’s 200K window.
- FP8 Inference: Deploying models with 8-bit precision cuts cloud costs by 40% compared to 16-bit rivals.
- Reinforcement Learning at Scale: R1’s self-improvement pipeline reduces reliance on expensive human feedback—a weakness for Anthropic’s Constitutional AI.
This has led to below advantages over other available models in the market:
- Cheaper: Traditional AI models often require extensive computational resources, which can be expensive to maintain. DeepSeek has implemented several strategies ( FP8 Quantization and Dynamic Memory Management) to lower these costs.
- Faster: Speed is another critical factor in AI inference, particularly for applications that need real-time decision-making. Using Multi-Head Latent Attention (MLA) optimization, DeepSeek’s models can process inputs much faster than their predecessors. This ability is crucial for applications like autonomous vehicles or financial trading systems. Delays can lead to missed opportunities or critical errors in these contexts.
- Longer: Traditional models often struggle with long sequences of data due to memory constraints. Nonetheless, with innovations like MLA, DeepSeek’s models can manage context windows that extend up to 1 million tokens. Models can keep longer contexts. This means they can analyze and draw insights from larger datasets without sacrificing detail or accuracy. This is particularly beneficial in fields like healthcare or legal analysis, where comprehending extensive information is essential.
These advances let DeepSeek undercut OpenAI’s $200/month subscription with a freemium model, driving 1M+ app downloads in days!
The cost disruption by DeepSeek V3

Source: Statista
DeepSeek’s \$5.6M training cost for V3 undercuts competitors by orders of magnitude:
- Meta Llama 3.1: \$60M+ (30M GPU-hours)
- Google Gemini Ultra: \$300M+ (estimated)
- OpenAI o1: \$120M+ (based on H100 cluster analysis)
This efficiency stems from:
- Hardware Agnosticism: Optimized for older H800 GPUs vs rivals’ H100 dependence[1]
- Algorithmic Co-design: Architectural choices informed by cluster topology
- Open Ecosystem: Community contributions improving post-training alignment
Geopolitical Shockwaves: Challenging the Export Control Regime
The ongoing geopolitical tensions, particularly between the United States and China, have led to significant shifts in global trade dynamics. They prompted the implementation of stringent export control measures.
Yet, DeepSeek’s success has ignited debates about U.S. chip export controls:
- H800 Loophole: V3 was trained on Nvidia’s H800 GPUs, which were legal for export until 2024. This exposed flaws in Biden’s ‘small yard, high fence‘ strategy. The \$5.6M training cost proves frontier models don’t need inaccessible supercomputers.
- Military Implications: At $5.6M per model, even sanctioned entities could replicate V3—undermining the premise that AI supremacy requires unfettered chip access.
- Economic Warfare Critics: Some argue export controls aim to stifle China’s civilian AI sector. Nevertheless, DeepSeek proves Chinese firms can innovate under constraints.
Anthropic’s CEO noted that the 2026-2027 window becomes critical. Yet, DeepSeek’s progress suggests China may close the gap faster than anticipated.
While Nvidia’s stock drop attracted headlines, the deeper disruption lies in:
- Inference Economics: R1’s \$0.12/hour cost enables mass-market adoption vs o1’s premium pricing.
- Edge AI Potential: Compact architectures allow smartphone deployment.
- Research Democratization: Open weights accelerate global AI safety efforts.
OpenAI risks losing developer mindshare as projects like DeepSeek-R1-Zero show open models can achieve frontier performance without corporate-scale resources.
Do you think NVIDIA’s high-performance premium chips will go waste? – let me know in the comments!
The Future of AI: Less Compute, More Ingenuity
DeepSeek’s rise signals a paradigm shift:
- Post-Training Dominance: While rivals focus on pre-training, DeepSeek’s reinforcement fine-tuning extracts maximal capability from smaller models12.
- Democratization: Low-cost training empowers startups and academia, challenging the ‘big tech monopoly’ narrative.
- Nvidia’s Dilemma: If inference, not training, drives future compute demand, Nvidia’s data center growth may slow. However, cheaper tokens could expand usage (e.g., AI generating 10x more tokens per query).
DeepSeek hasn’t just built better models—it’s rewritten the rules.
By marrying architectural ingenuity (MoE, MLA) with algorithmic efficiency (self-taught reasoning, FP8), it achieved frontier performance at bootstrap costs.
For OpenAI and Anthropic, the lesson is clear: The 2020s-era “scale is all you need” mantra is obsolete. Meanwhile, policymakers must grapple with the reality that export controls can’t bottle up algorithmic progress—a truth DeepSeek just made undeniable.
The AI race is no longer purely about who has the most GPUs.
It’s about who uses them best.
Right now, that’s DeepSeek.
What do you think? – let me know in the comments!
The Road Ahead – what’s the takeaway?
DeepSeek’s trajectory suggests several industry shifts:
- Specialized Hardware Decline: Efficient models reduce reliance on latest GPUs.
- Reinforcement Learning Dominance: Self-improving systems bypass human data limits.
- Hybrid Intelligence: Visible reasoning tokens enabling human-AI collaboration.
CEO Liang Wenfeng stated at the Beijing AI Symposium,
True intelligence augmentation requires transparency first.
This is the philosophy that positions DeepSeek as the anti-thesis to OpenAI’s closed approach.
The coming months will test whether Western labs can match this efficiency leap. 2025 might become the year open models redefine AI’s power dynamics.
What do you think about DeepSeek V3’s development?
I have tried to understand the whole fiasco by reading available materials, news, and Perplexity. I have also read papers which I have linked across this guide.
If there is any issue, correction, or doubt, please comment. I would be happy to fix it or clear any doubt you have.
At Applied AI Tools, we want to make learning accessible. You can discover how to use the many available AI software for your personal and professional use. If you have any questions – email to content@merrative.com and we will cover them in our guides and blogs.
Learn more about AI concepts:
- 2 key insights on the future of software development – Transforming Software Design with AI Agents
- Explore AI Agents – What is OpenAI o3-mini
- Learn what is tree of thoughts prompting method
- Make the most of ChatGPT – 5 Free ChatGPT Features For Prompt Management
- Learn what influencers and experts think about AI’s impact on future of work – 15+ Generative AI quotes on future of work, impact on jobs and workforce productivity
You can subscribe to our newsletter to get notified when we publish new guides!
This blog post is written using resources of Merrative. We are a publishing talent marketplace that helps you create publications and content libraries.
Get in touch if you would like to create a content library like ours. We specialize in the niche of Applied AI, Technology, Machine Learning, or Data Science.
Leave a Reply